
For unto every one that hath shall be given, and he shall have abundance: but from him that hath not shall be taken away even that which he hath. Matthew 25:29
So you’ve slaved over your departmental submission for REF2014, and shortly will be handing it in. A nervous few months await before the results are announced. You’ve sweated blood over deciding whether staff publications or impact statements will be graded as 1*, 2*, 3* or 4*, but it’s not possible to predict how the committee will judge them, nor, more importantly, how these ratings will translate into funding. In the last round of evaluation, in 2008, a weighted formula was used, such that a submission earned 1 point for every 2* output, 3 points for every 3* output, and 7 points for every 4* output. Rumour has it that this year there may be no money for 2* outputs and even more for 4*. It will be more complicated than this, because funding allocations will also take into account ratings of ‘impact statements’, and the ‘environment’.
I’ve blogged previously about concerns I have with the inefficiency of the REF2014 as a method for allocating funds. Today I want to look at a different issue: the extent to which the REF increases disparities between universities over time. To examine this, I created a simulation which made a few simple assumptions. We start with a sample of 100 universities, each of which is submitting 50 staff in a Unit of Assessment. At the outset, we start with all universities equal in terms of the research quality of their staff: they are selected at random from a pool of possible staff whose research quality is normally distributed. Funding is then allocated according to the formula used in RAE2008. The key feature of the simulation is that over every assessment period there is turnover of staff (estimated at 10% in simulation shown here), and universities with higher funding levels are able to recruit replacement staff with higher scores on the research quality scale. These new staff are then the basis for computing funding allocations in the next cycle – and so on, through as many cycles as one wishes. This simulation shows that funding starts out fairly normally distributed, but as we progress through each cycle, it becomes increasingly skewed, with the top-performers moving steadily away from the rest (Figure A). In the graphs, funding is shown over time for universities grouped in deciles, i.e., bands of 10 universities after ranking by funding level.
 |
| Simulation: Mean income for universities in each of 10 deciles over 6 funding cycles |
We could do things differently. Figure B shows how tweaking the funding model could avoid opening up such a wide gulf between the richest and poorest, and retain a solid core of middle-ranking universities.
 |
| Simulation using linear weighting of * levels. Each line is average for institutions in a given decile |
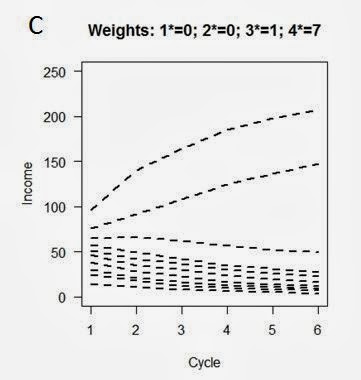 |
| Simulation where 4* outputs get favoured. Each line is average for institutions in a given decile |
However, given that finances are always limited, there will be a cost to the focus on an elite; the middle-ranking universities will get less funding, and be correspondingly less able to attract high-calibre researchers. And it could be argued that we don’t just need an elite: we need a reasonable number of institutions in which there is a strong research environment, where more senior researchers feel valued and their graduate students and postdocs are encouraged to aim high. Our best strategy for retaining international competitiveness might be by fostering those who are doing well but have potential to do even better. In any case, much research funding is awarded through competition for grants, and most of this goes to people in elite institutions, so these places will not be starved of income if we were to adopt a more balanced system of awarding central funds.
What worries me most is that I haven’t been able to find any discussion of this issue – namely, whether the goal of a funding formula should be to focus on elite institutions or distribute funds more widely. The nearest thing I’ve found so far is a paper analysing a parallel issue in grant awards (Fortin & Curry, 2013) – which comes to the conclusion that broader distribution of smaller grants is more effective than narrowly distributed large grants. Very soon, somebody somewhere is going to decide on the funding formula, and if rumours are to be believed, it will widen the gap between the haves and have-nots even further. I'm concerned that if we continue to concentrate funding only in those institutions with a high proportion of research superstars, we may be creating an imbalance in our system of funding that will be bad for UK research in the long run.
Reference
Fortin JM, & Currie DJ (2013). Big Science vs. Little Science: How Scientific Impact Scales with Funding. PloS one, 8 (6) PMID: 23840323



{kind=link}